You are given an integer n. There is an undirected graph with n nodes, numbered from 0 to n - 1. You are given a 2D integer array edges where edges[i] = [a<sub>i</sub>, b<sub>i</sub>] denotes that there exists an undirected edge connecting nodes a<sub>i</sub> and b<sub>i</sub>.
Return the number of pairs of different nodes that are unreachable from each other.
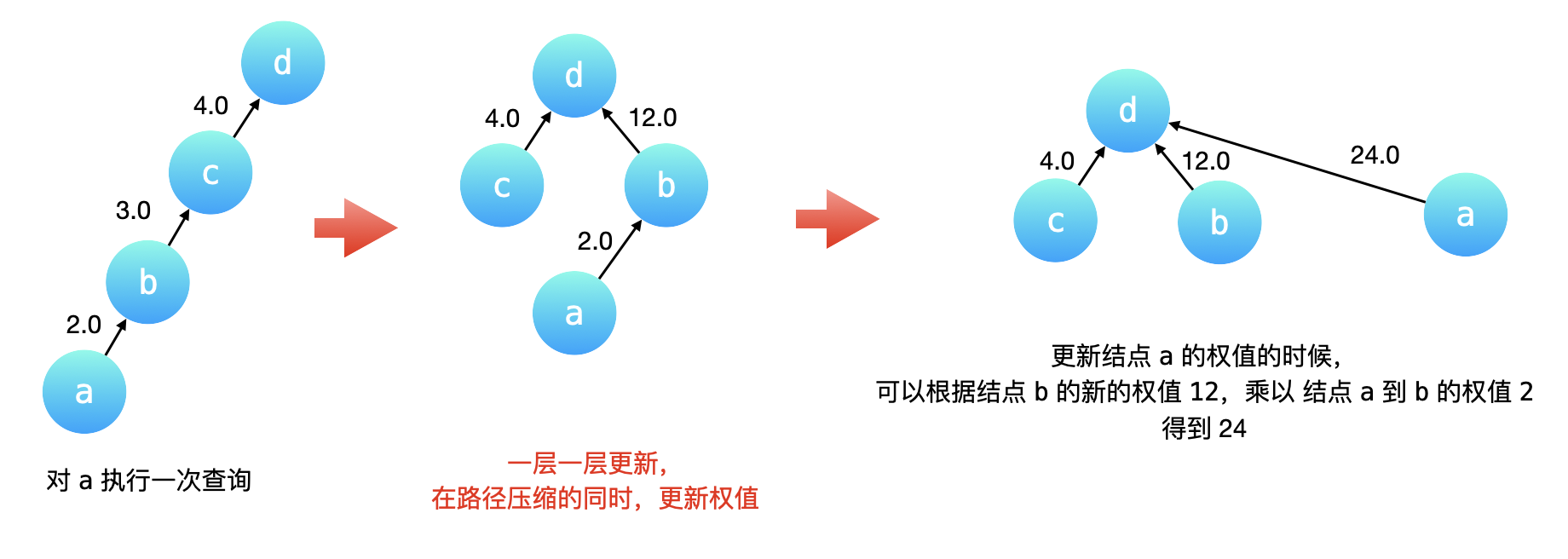
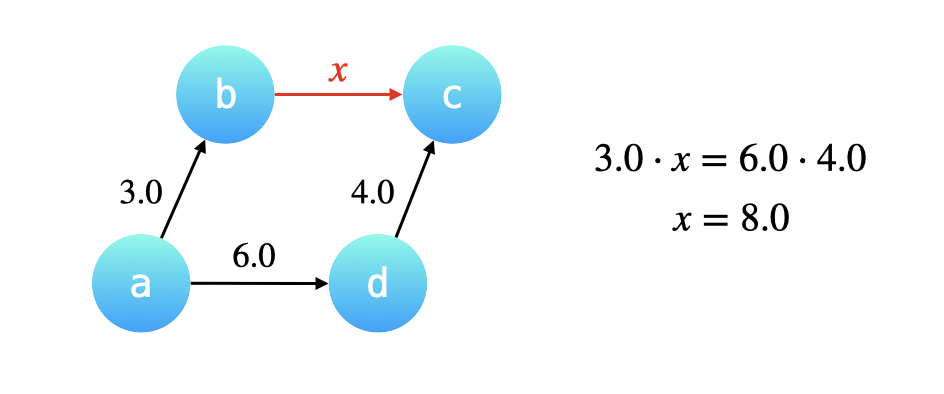
You are given an array of variable pairs equations and an array of real numbers values, where equations[i] = [Ai, Bi] and values[i] represent the equation Ai / Bi = values[i]. Each Ai or Bi is a string that represents a single variable.
You are also given some queries, where queries[j] = [Cj, Dj] represents the jth query where you must find the answer for Cj / Dj = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.
You are given an array points representing integer coordinates of some points on a 2D-plane, where points[i] = [xi, yi].
The cost of connecting two points [xi, yi] and [xj, yj] is the manhattan distance between them: |xi - xj| + |yi - yj|, where |val| denotes the absolute value of val.
Return the minimum cost to make all points connected. All points are connected if there is exactly one simple path between any two points.