You are given an integer array coins representing coins of different denominations and an integer amount representing a total amount of money.
Return the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return -1.
You may assume that you have an infinite number of each kind of coin.
Given an integer array nums, you need to find one continuous subarray that if you only sort this subarray in ascending order, then the whole array will be sorted in ascending order.
Return the shortest such subarray and output its length.
Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.
According to the definition of LCA on Wikipedia: “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow a node to be a descendant of itself).”
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ classSolution { public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if(root == null) returnnull; if(root == p) return p; //found target and return if(root == q) return q; //found target and return TreeNodeleft= lowestCommonAncestor(root.left, p, q); //search left branch TreeNoderight= lowestCommonAncestor(root.right, p, q); //search right branch if(left == null) return right; //if left not found target, return the right branch elseif(right == null) return left; //if right not found target, return the left branch elsereturn root; //if both found target, return the root } }
Given two integer arrays preorder and inorder where preorder is the preorder traversal of a binary tree and inorder is the inorder traversal of the same tree, construct and return the binary tree.
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
For example, “ace” is a subsequence of “abcde”. A common subsequence of two strings is a subsequence that is common to both strings.
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Given the root of a binary tree and an integer targetSum, return all root-to-leaf paths where the sum of the node values in the path equals targetSum. Each path should be returned as a list of the node values, not node references.
A root-to-leaf path is a path starting from the root and ending at any leaf node. A leaf is a node with no children.
Given the root of a binary tree, return the zigzag level order traversal of its nodes’ values. (i.e., from left to right, then right to left for the next level and alternate between).
Given a string s and a dictionary of strings wordDict, return true if s can be segmented into a space-separated sequence of one or more dictionary words.
Note that the same word in the dictionary may be reused multiple times in the segmentation.
A message containing letters from A-Z can be encoded into numbers using the following mapping:
‘A’ -> “1” ‘B’ -> “2” … ‘Z’ -> “26” To decode an encoded message, all the digits must be grouped then mapped back into letters using the reverse of the mapping above (there may be multiple ways). For example, “11106” can be mapped into:
“AAJF” with the grouping (1 1 10 6)
“KJF” with the grouping (11 10 6) Note that the grouping (1 11 06) is invalid because “06” cannot be mapped into ‘F’ since “6” is different from “06”.
Given a string s containing only digits, return the number of ways to decode it.
The test cases are generated so that the answer fits in a 32-bit integer.
Given an integer array nums, return the length of the longest strictly increasing subsequence.
A subsequence is a sequence that can be derived from an array by deleting some or no elements without changing the order of the remaining elements. For example, [3,6,2,7] is a subsequence of the array [0,3,1,6,2,2,7].
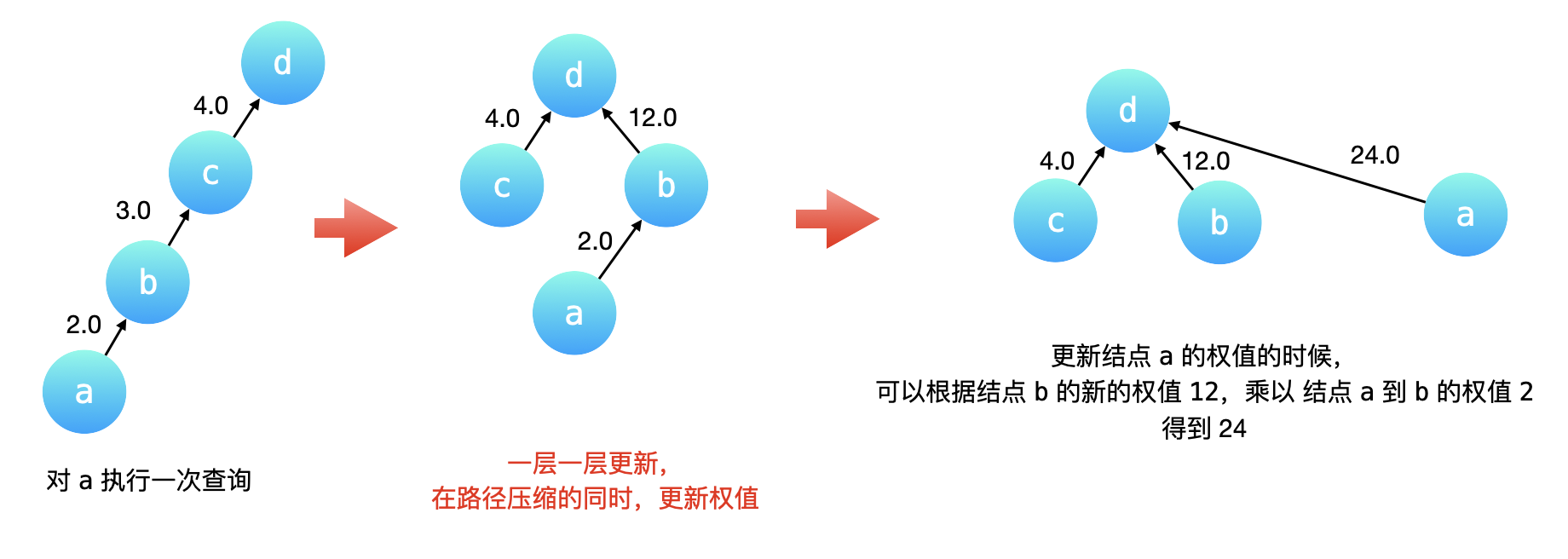
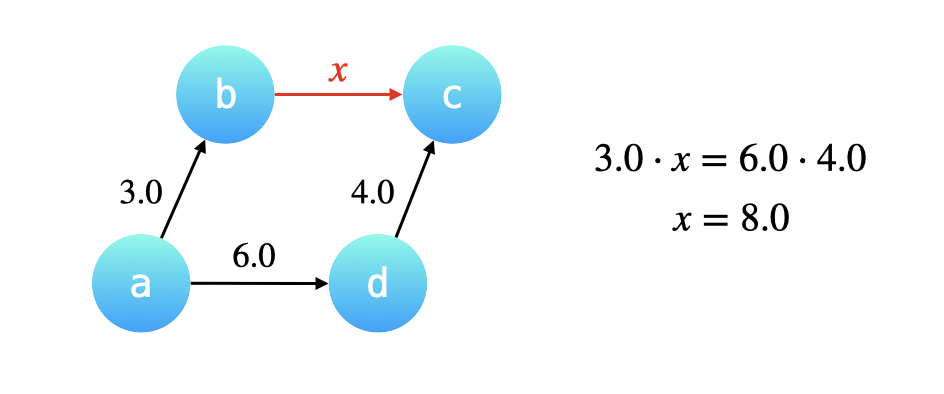
You are given an array of variable pairs equations and an array of real numbers values, where equations[i] = [Ai, Bi] and values[i] represent the equation Ai / Bi = values[i]. Each Ai or Bi is a string that represents a single variable.
You are also given some queries, where queries[j] = [Cj, Dj] represents the jth query where you must find the answer for Cj / Dj = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.