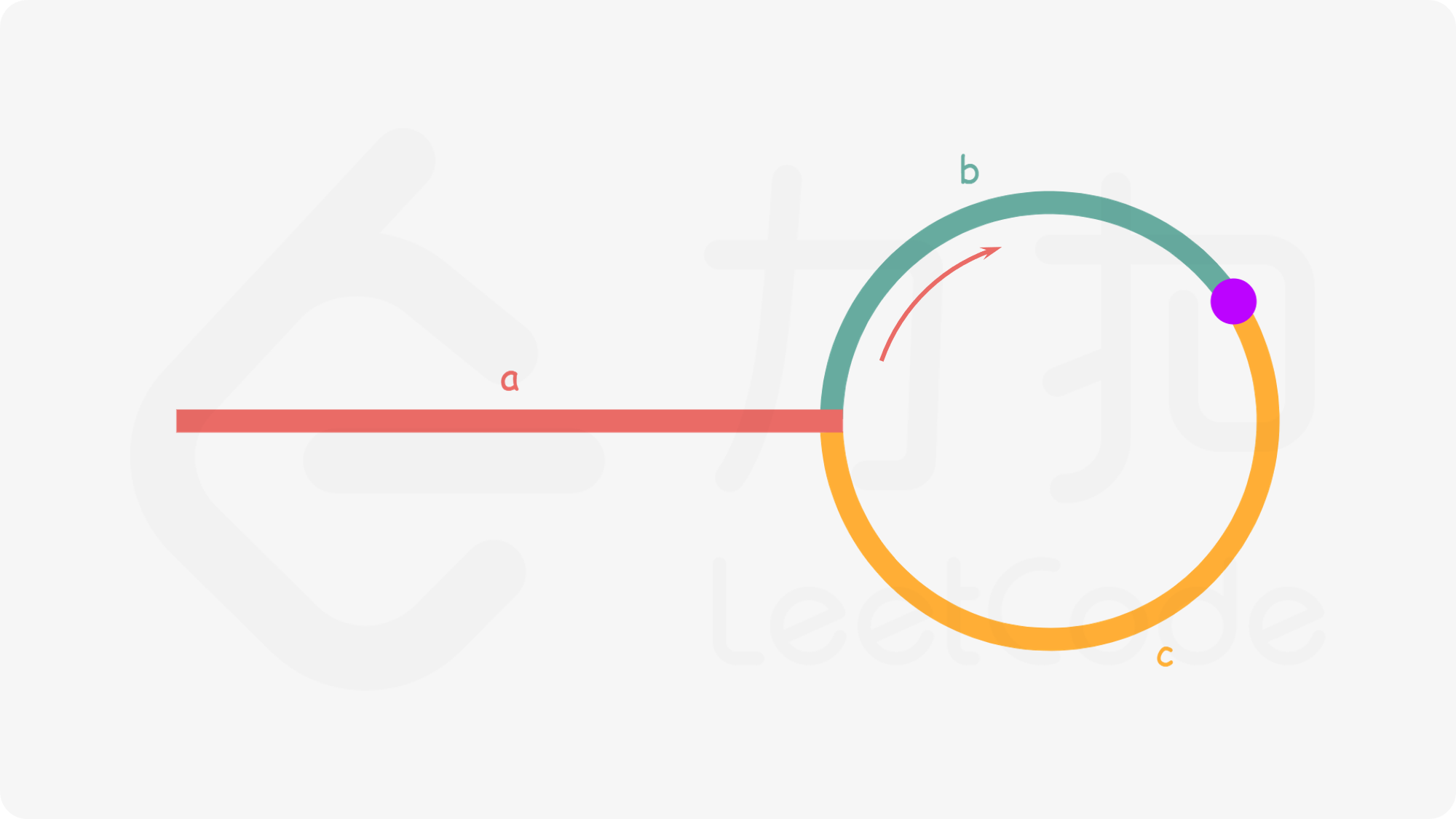Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
For example, “ace” is a subsequence of “abcde”. A common subsequence of two strings is a subsequence that is common to both strings.
Given the root of a binary tree, return the zigzag level order traversal of its nodes’ values. (i.e., from left to right, then right to left for the next level and alternate between).
Given a string s and a dictionary of strings wordDict, return true if s can be segmented into a space-separated sequence of one or more dictionary words.
Note that the same word in the dictionary may be reused multiple times in the segmentation.
A message containing letters from A-Z can be encoded into numbers using the following mapping:
‘A’ -> “1” ‘B’ -> “2” … ‘Z’ -> “26” To decode an encoded message, all the digits must be grouped then mapped back into letters using the reverse of the mapping above (there may be multiple ways). For example, “11106” can be mapped into:
“AAJF” with the grouping (1 1 10 6)
“KJF” with the grouping (11 10 6) Note that the grouping (1 11 06) is invalid because “06” cannot be mapped into ‘F’ since “6” is different from “06”.
Given a string s containing only digits, return the number of ways to decode it.
The test cases are generated so that the answer fits in a 32-bit integer.
Given an integer array nums, return the length of the longest strictly increasing subsequence.
A subsequence is a sequence that can be derived from an array by deleting some or no elements without changing the order of the remaining elements. For example, [3,6,2,7] is a subsequence of the array [0,3,1,6,2,2,7].
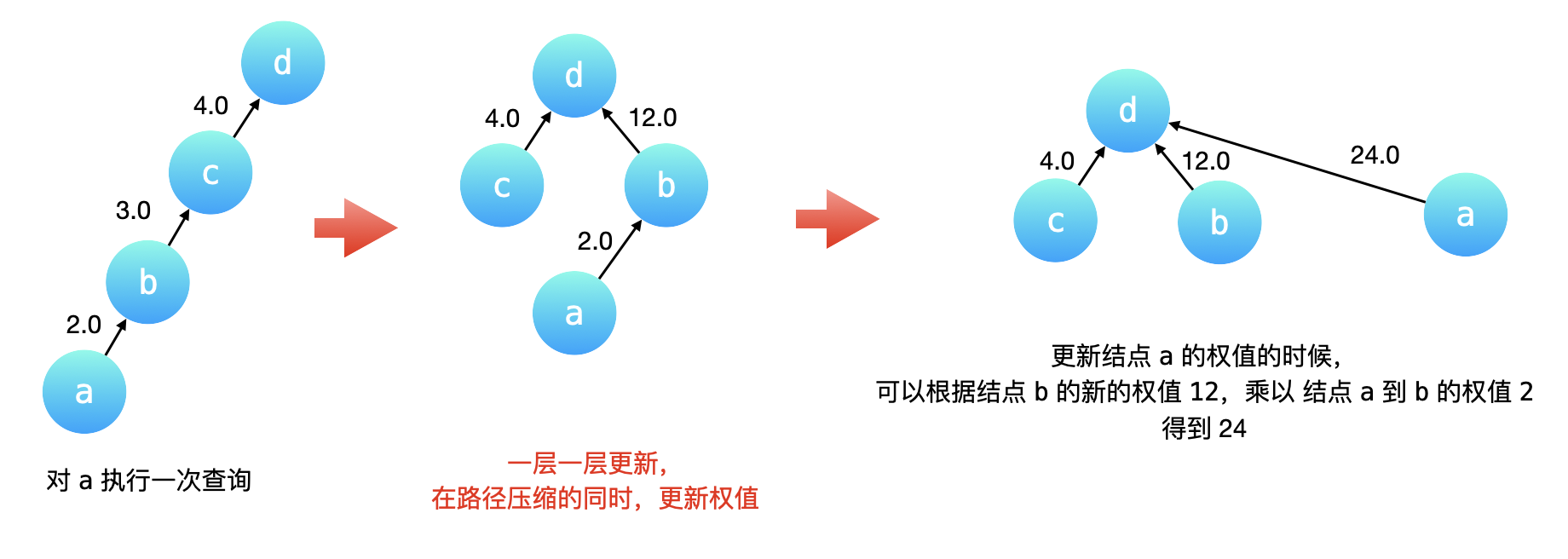
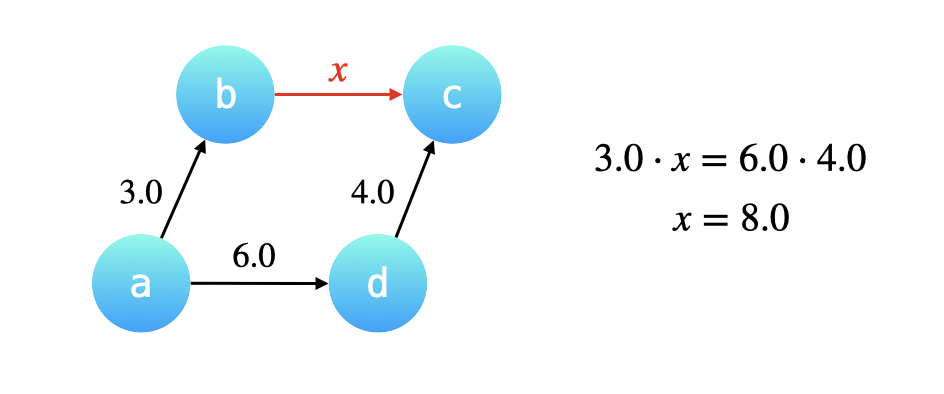
You are given an array of variable pairs equations and an array of real numbers values, where equations[i] = [Ai, Bi] and values[i] represent the equation Ai / Bi = values[i]. Each Ai or Bi is a string that represents a single variable.
You are also given some queries, where queries[j] = [Cj, Dj] represents the jth query where you must find the answer for Cj / Dj = ?.
Return the answers to all queries. If a single answer cannot be determined, return -1.0.
Note: The input is always valid. You may assume that evaluating the queries will not result in division by zero and that there is no contradiction.
You are a hiker preparing for an upcoming hike. You are given heights, a 2D array of size rows x columns, where heights[row][col] represents the height of cell (row, col). You are situated in the top-left cell, (0, 0), and you hope to travel to the bottom-right cell, (rows-1, columns-1) (i.e., 0-indexed). You can move up, down, left, or right, and you wish to find a route that requires the minimum effort.
A route’s effort is the maximum absolute difference in heights between two consecutive cells of the route.
Return the minimum effort required to travel from the top-left cell to the bottom-right cell.
Design your implementation of the linked list. You can choose to use a singly or doubly linked list. A node in a singly linked list should have two attributes: val and next. val is the value of the current node, and next is a pointer/reference to the next node. If you want to use the doubly linked list, you will need one more attribute prev to indicate the previous node in the linked list. Assume all nodes in the linked list are 0-indexed.
Implement the MyLinkedList class:
MyLinkedList() Initializes the MyLinkedList object.
int get(int index) Get the value of the indexth node in the linked list. If the index is invalid, return -1.
void addAtHead(int val) Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list.
void addAtTail(int val) Append a node of value val as the last element of the linked list.
void addAtIndex(int index, int val) Add a node of value val before the indexth node in the linked list. If index equals the length of the linked list, the node will be appended to the end of the linked list. If index is greater than the length, the node will not be inserted.
void deleteAtIndex(int index) Delete the indexth node in the linked list, if the index is valid.
/** * Your MyLinkedList object will be instantiated and called as such: * MyLinkedList obj = new MyLinkedList(); * int param_1 = obj.get(index); * obj.addAtHead(val); * obj.addAtTail(val); * obj.addAtIndex(index,val); * obj.deleteAtIndex(index); */
You are given an integer array nums. You are initially positioned at the array’s first index, and each element in the array represents your maximum jump length at that position.
Return true if you can reach the last index, or false otherwise.
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed. All houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, adjacent houses have a security system connected, and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given an integer array nums representing the amount of money of each house, return the maximum amount of money you can rob tonight without alerting the police.
Given a linked list, swap every two adjacent nodes and return its head. You must solve the problem without modifying the values in the list’s nodes (i.e., only nodes themselves may be changed.)
You are given an array points representing integer coordinates of some points on a 2D-plane, where points[i] = [xi, yi].
The cost of connecting two points [xi, yi] and [xj, yj] is the manhattan distance between them: |xi - xj| + |yi - yj|, where |val| denotes the absolute value of val.
Return the minimum cost to make all points connected. All points are connected if there is exactly one simple path between any two points.
Given the head of a linked list, return the node where the cycle begins. If there is no cycle, return null.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail’s next pointer is connected to (0-indexed). It is -1 if there is no cycle. Note that pos is not passed as a parameter.